2.0 added a supervisor/worker architecture for analyzing multiple binaries simultaneously. 2.1 introduced progressive tool discovery so the LLM could find specialized tools on demand instead of loading ~195 schemas at startup. 2.2 added meta-tools that let the LLM write multi-step analysis scripts, issue bulk operations, and persist state across sessions through a daemon.
Each release solved a real friction point. But that progression revealed something about the interface itself. The tools the LLM actually calls (decompile this function, get cross-references to that address, rename this symbol, search for strings matching this pattern) described reverse engineering in the abstract, not IDA in particular. IDA was the engine behind those tools, but the tool surface itself was generic. An LLM asking to decompile main doesn’t care whether the answer comes from Hex-Rays or Ghidra’s decompiler. It cares about the pseudocode.
That realization is why ida-mcp is now re-mcp (reverse engineering MCP). Version 3.0 ships with a full Ghidra backend alongside the existing IDA Pro backend, with a shared tool interface that makes LLM workflows portable across both.
The most common response I heard after publishing ida-mcp was some variation of “this looks great, but I don’t have an IDA license.” IDA Pro is the industry standard for binary analysis, but it costs thousands of dollars per seat. For students, independent researchers, CTF players, and hobbyists, that puts LLM-driven reverse engineering out of reach before it even starts.
Ghidra, released by the NSA as open source in 2019, has become the primary free alternative. It supports dozens of processor architectures, its decompiler is capable, and it has an active community building extensions and loaders. By adding Ghidra as a backend, re-mcp makes everything from 2.0 through 2.2 (multi-database analysis, progressive tool discovery, execute scripts, batch operations) available to anyone willing to install a free tool and a JDK.
The Ghidra backend requires Python 3.12+, Ghidra 12+, and JDK 21+. Ghidra’s install path is found automatically from the GHIDRA_INSTALL_DIR environment variable or platform-specific default locations.
uv tool install re-mcp-ghidra
Then configure your MCP client:
{
"mcpServers": {
"ghidra": {
"command": "uvx",
"args": ["re-mcp-ghidra"]
}
}
}
From there, everything works the way it did with IDA. Open a binary, wait for analysis to complete, and start asking questions.
The meta-tools from 2.2 work on the Ghidra backend too. Here’s an execute script that finds functions referencing error strings and summarizes them:
strings = await invoke("find_code_by_string", {
"pattern": "invalid|error|fail", "limit": 50
})
seen = set()
results = []
for hit in strings["items"]:
fn = hit.get("function_name", "")
if not fn or fn in seen:
continue
seen.add(fn)
decomp = await invoke("decompile_function", {
"address": hit["function_address"]
})
results.append({
"function": decomp["function_name"],
"address": decomp["address"],
"matched_string": hit["string_value"],
"lines": len(decomp["decompiled_code"].splitlines())
})
return {"functions_with_error_strings": results}
One tool call. The LLM gets back every function that references an error string, with its decompiled size, ready for triage. The same workflow pattern from the 2.2 post applies here (the only difference being response field names like decompiled_code vs. pseudocode).
There’s a practical reason to support both backends even if you already have an IDA license. IDA and Ghidra have different analysis engines, different heuristics for function boundary detection, different type propagation strategies. Running the same binary through both and comparing the output is a common practice in professional reverse engineering; each tool catches things the other misses.
With re-mcp, you configure both servers, and the LLM can open the same binary in each and compare function lists, decompiler output, and cross-references across the two.
Both backends implement the same core tool interface: identical tool names, identical parameters, and the same categories of information in responses (though individual field names in responses may differ slightly between engines). From a user’s perspective, it doesn’t matter which engine is running: the LLM issues the same tool calls and returns comparable results either way.
The shared surface covers the operations that define a reverse engineering session:
search_tools, get_schema, call, execute, batchAn execute script that crawls error strings, decompiles referencing functions, and renames them follows the same logic on either engine; scripts only need to adjust for the field name differences noted above.
Each backend also retains capabilities specific to its engine. The IDA backend keeps everything from the 2.x releases: IDAPython scripting via run_script, file region mapping, executable rebuilding, IDC evaluation, and the eight guided prompts for structured analysis workflows. The Ghidra backend brings its own strengths: Function ID for automatic library function identification and data type archive support.
re-mcp is a monorepo with three packages: re-mcp-core (supervisor, transport, meta-tools), re-mcp-ida (IDA Pro backend wrapping idalib), and re-mcp-ghidra (Ghidra backend wrapping pyghidra). The core package doesn’t depend on IDA or Ghidra. Backends are discovered through Python entry points, so you install only what you need:
# IDA users
uv tool install re-mcp-ida
# Ghidra users
uv tool install re-mcp-ghidra
# Both
uv tool install re-mcp --with re-mcp-ida --with re-mcp-ghidra
Future backends (Binary Ninja, radare2, or something that doesn’t exist yet) would slot in as additional packages implementing the same worker interface, with no changes to the core or any existing backend.
re-mcp 3.0 switches the default transport to direct stdio: one session, workers terminate on disconnect. This is simpler to set up than the HTTP daemon that ida-mcp 2.2 defaulted to, and it works universally with every MCP client. For workflows that need persistence, the daemon is still available via proxy or serve subcommands (e.g., re-mcp-ghidra serve, re-mcp-ida serve). The transport mode is independent of the backend; all options work the same for re-mcp-ida, re-mcp-ghidra, and the unified re-mcp --backend <name> command.
The legacy ida-mcp PyPI package now redirects to re-mcp-ida. Existing installations continue to work after upgrading:
uv tool install --upgrade ida-mcp
# or install directly
uv tool install re-mcp-ida
The MCP tool interface is backward compatible. Existing execute scripts, batch operations, and direct tool calls work without changes. Requirements are unchanged: IDA Pro 9+ with Python 3.12+. The main visible difference is the entry point name (ida-mcp becomes re-mcp-ida), though the old name continues to work as an alias.
Environment variables follow the same pattern as before, prefixed per backend. IDA_MCP_ variables carry over unchanged for the IDA backend; the Ghidra backend uses GHIDRA_MCP_ with the same suffixes.
If you run into issues or have feature requests, please open an issue on GitHub.
IDA Pro and Hex-Rays are trademarks of Hex-Rays SA. Ghidra is developed by the National Security Agency. re-mcp is an independent project and is not affiliated with or endorsed by Hex-Rays or the NSA.
]]>In 2.1, each action was a discrete tool call: decompile this function, get cross-references to that address, rename this symbol. Every step was a full MCP round trip. Every intermediate result landed in the context window. An analysis workflow that a human would express as a ten-line IDAPython script became thirty sequential tool calls, each waiting for the previous one to return before the LLM could decide what to do next. The LLM knew what it wanted to do, but it couldn’t say it all at once.
2.2 introduces meta-tools that let the LLM operate at a higher level of abstraction: writing multi-step analysis scripts, issuing bulk operations, and calling tools it discovers at runtime. It also makes the server persistent, so analysis state survives across sessions. And for the first time, ida-mcp can analyze firmware and raw binaries directly.
execute: sandboxed analysis scriptsexecute accepts Python code that calls IDA tools through await invoke(name, params), with full control flow: loops, conditionals, regex, struct unpacking, list comprehensions. Individual tools are still the right choice for simple operations, but for multi-step analysis, the LLM becomes a script writer.
Consider a common reverse engineering task: finding every function that references an error string and understanding how each one handles the error. In 2.1, this was a multi-step conversation:
get_strings with a filter → get back 40 matching stringsget_xrefs_to for the first string address → get back 3 cross-referencesdecompile_function for each referencing function → get back pseudocodeThat’s potentially 160+ tool calls, each a full round trip, with the LLM holding intermediate addresses in context between calls. If the context window fills up mid-workflow, earlier results get compacted and the LLM loses track of where it was.
With execute, the same workflow is a single tool call:
strings = await invoke("get_strings", {"filter": "error|fail|panic"})
results = []
for s in strings["strings"]:
xrefs = await invoke("get_xrefs_to", {"address": s["address"]})
for xref in xrefs["xrefs"]:
decomp = await invoke("decompile_function", {"address": xref["from"]})
results.append({
"string": s["value"],
"function": decomp["name"],
"pseudocode": decomp["pseudocode"]
})
return results
One round trip. The LLM gets back a structured result containing every error-handling function with its decompiled pseudocode. No intermediate state to track, no context window spent on addresses it only needed temporarily. And if the LLM decides the approach is wrong, it’s only wasted one tool call finding out.
Any “get a list, then process each item” workflow collapses from O(n) tool calls to one. The bigger gain is for workflows that don’t reduce to sequential calls: conditional logic, data transformation, or cross-referencing between results.
Automated renaming based on string references:
A stripped binary might have thousands of sub_* functions with no meaningful names, but many of them reference string literals that hint at their purpose. A human analyst would scan through decompiled output, spot a string like "failed to parse header", and rename the function accordingly. With execute, the LLM can do this systematically across the entire binary in a single tool call:
import re
funcs = await invoke("list_functions", {"filter": "sub_"})
renamed = []
for func in funcs["functions"]:
decomp = await invoke("decompile_function", {"address": func["address"]})
strings = re.findall(r'"([^"]{4,})"', decomp["pseudocode"])
if strings:
candidate = re.sub(r'[^a-zA-Z0-9_]', '_', strings[0])[:40]
await invoke("rename_function", {
"address": func["address"],
"new_name": f"uses_{candidate}"
})
renamed.append({"old": func["name"], "new": f"uses_{candidate}"})
return {"renamed": len(renamed), "functions": renamed}
The names this generates are rough: a first pass rather than a final answer. But uses_failed_to_parse_header is vastly more useful than sub_140001A30 when you’re trying to understand a binary’s structure, and the LLM can refine them in a second pass once it understands the broader architecture.
Cross-database patch diffing:
Patch analysis requires comparing function lists between two versions of a library, identifying what was added or removed, and diffing the implementations that exist in both. Without execute, the LLM would pull function lists from each database in separate tool calls, hold both in context, compute set differences itself, and decompile changed functions one at a time. Dozens of round trips, large intermediate results sitting in context.
With execute, the entire triage happens server-side:
old_funcs = await invoke("list_functions", {"database": "libcrypto_1.1.1"})
new_funcs = await invoke("list_functions", {"database": "libcrypto_1.1.2"})
old_names = {f["name"] for f in old_funcs["functions"]}
new_names = {f["name"] for f in new_funcs["functions"]}
added = sorted(new_names - old_names)
removed = sorted(old_names - new_names)
# Spot-check shared functions for implementation changes
changed = []
for name in sorted(old_names & new_names)[:30]:
old_dec = await invoke("decompile_function", {
"address": name, "database": "libcrypto_1.1.1"
})
new_dec = await invoke("decompile_function", {
"address": name, "database": "libcrypto_1.1.2"
})
if old_dec["pseudocode"] != new_dec["pseudocode"]:
changed.append(name)
return {
"added": added[:50],
"removed": removed[:50],
"changed": changed,
"summary": {
"added": len(added),
"removed": len(removed),
"shared_checked": min(30, len(old_names & new_names)),
"shared_changed": len(changed)
}
}
The database parameter override lets a single execute block work across multiple open databases. Each invoke call can target a different database by name. The LLM gets back a structured summary of what changed between versions, and can then drill into specific changed functions in follow-up calls. The set operations, sorting, and conditional comparison all happen server-side rather than burning context on intermediate data the LLM only needs to pass through.
The code runs in a RestrictedPython sandbox. The LLM can import re, struct, json, math, collections, itertools, functools, and a few other safe standard library modules. It cannot access the filesystem, open network connections, or spawn subprocesses. Attribute access to dunder names (__class__, __globals__, __code__) is blocked at the AST level, closing Python sandbox escape hatches. Print output is capped at ~1 MiB to prevent runaway loops from exhausting worker memory.
Database lifecycle tools (open_database, close_database, wait_for_analysis) are blocked inside the sandbox; an execute block shouldn’t be spawning or tearing down workers as a side effect. The meta-tools themselves (execute, batch, call) are also blocked to prevent recursion. Everything else (decompilation, disassembly, renaming, commenting, type manipulation, structure editing) is available through await invoke().
A failed invoke call raises a Python exception that the script can catch with try/except, or that terminates the block with an error message if uncaught.
If the LLM writes an execute block that contains a single invoke call with no processing logic around it, the server detects this and returns a hint suggesting the simpler call meta-tool instead. Small nudges like this help the LLM learn the right tool for the job over the course of a session.
batch: bulk operations without scripting overheadNot every multi-call workflow needs control flow. Sometimes it’s the same operation twenty times: decompile a list of functions, rename a set of symbols, add comments at known addresses. For these, execute is overkill: sandbox overhead just to loop over a list. batch handles this directly: a list of operations, run sequentially with per-item error handling.
{
"operations": [
{"tool": "decompile_function", "params": {"address": "0x401000"}},
{"tool": "decompile_function", "params": {"address": "0x401100"}},
{"tool": "rename_function", "params": {"address": "0x401000", "new_name": "parse_header"}},
{"tool": "rename_function", "params": {"address": "0x401100", "new_name": "validate_checksum"}},
{"tool": "set_comment", "params": {"address": "0x401000", "comment": "Entry point for packet parsing"}},
{"tool": "set_comment", "params": {"address": "0x401100", "comment": "CRC-32 validation"}}
]
}
Up to 50 operations per call, mixing different tools freely. This example decompiles two functions, renames them, and annotates them: six operations that would have been six separate tool calls in 2.1, collapsed into one.
In 2.1, batching was baked into individual tools: decompile_function accepted up to 50 addresses, get_xrefs_to accepted up to 50, each with its own batch parameter format. The LLM had to remember which tools supported batching and how each one worked. The unified batch meta-tool replaces all of that: a list of {tool, params} objects. Any tool can be batched.
stop_on_error controls whether the batch aborts on the first failure or continues collecting results. The default is to continue: if 30 functions are being renamed and one address is invalid, the other 29 still succeed. The response includes per-operation success/failure status, so the LLM can see exactly what failed and decide whether to retry or move on.
The split is straightforward: if there’s no data dependency between operations (the output of one doesn’t feed into another), the LLM uses batch. If the workflow chains outputs, filters intermediate results, or applies conditional logic, it writes an execute script.
call and get_schema: the discovery layer2.1 introduced progressive tool discovery: ~20 core tools registered upfront, the rest discoverable via search_tools and callable through call_tool. 2.2 refines this into a cleaner surface:
search_tools: regex search over tool names, descriptions, and tags. Returns compact signatures by default; pass detail="detailed" for descriptions or detail="full" for complete schemas.get_schema: fetch the full parameter schema for a specific tool by name, skipping the search when the LLM already knows what it wants.call: invoke any tool by name (renamed from call_tool), including hidden tools not in the client’s tool list.~25 tools are now pinned (up from ~20), and the total count is down to ~125 after 2.1’s resource consolidation. The remaining ~100 specialized tools are discoverable through search_tools and callable through call, batch, or execute.
Together, the five meta-tools form a hierarchy:
| Need | Meta-tool |
|---|---|
| Find a tool | search_tools |
| Check its parameters | get_schema |
| Call it once | call (or directly, if pinned) |
| Call many tools independently | batch |
| Chain tool outputs with logic | execute |
The LLM picks the right level without prompting. A quick rename uses a pinned tool directly. A bulk annotation uses batch. A multi-step investigation uses execute. When it needs something specialized (applying a calling convention, editing register variables), it searches, checks the schema, and calls through call.
The meta-tools only pay off if the server stays alive long enough to use them. In 2.1, ida-mcp ran as a stdio subprocess of the MCP client. When the client disconnected (closing an editor, cycling a session, restarting after a crash), the server process died and took all worker state with it. Every open database, every completed auto-analysis pass, every renamed function: gone. For quick, single-session analysis, this was acceptable. But reverse engineering work rarely fits in a single session. You open a binary, let auto-analysis run, rename a few hundred functions, apply types, and then come back the next day to continue. Or the session cycles for an unrelated reason and you lose everything.
The problem was worse in Claude Code, where subagents share a single MCP session. A subagent halfway through analyzing a firmware image (hundreds of functions renamed, types applied) loses everything when the session cycles. It reconnects, but has to reopen, re-analyze, and reconstruct its progress from whatever survived context compaction.
In 2.2, the server runs as a persistent HTTP daemon behind a lightweight stdio proxy:
LLM Client <──stdio──> Proxy <──HTTP──> Daemon
Workers + Databases
The first time an MCP client connects, the proxy spawns a daemon process and detaches it. Subsequent connections (including reconnections after a session cycle, from a different editor, or from a completely new conversation) reuse the running daemon. Workers and their databases persist across disconnects: renamed symbols, added comments, applied types all survive.
The daemon also supports collaboration across clients. If a human analyst has been annotating a binary through one MCP session, a second session connecting to the same daemon sees all those annotations immediately. The daemon doesn’t care who made the changes; it just maintains the databases.
The daemon listens on 127.0.0.1 with a per-instance 256-bit bearer token. The state file is written with 0600 permissions so only the spawning user can read the token. To stop the daemon:
ida-mcp stop
This is the default transport now. Existing MCP client configurations (ida-mcp as the command) work without changes. The proxy handles daemon lifecycle transparently.
ida-mcp could already open ELF, PE, and Mach-O files, where IDA auto-detects the architecture and load address from file headers. But firmware analysis (bootloaders, ROM dumps, flash extractions) starts with a blob of bytes and no metadata. Previously, you had to preprocess the binary in IDA’s GUI or write a loader script before ida-mcp could work with it. In 2.2, open_database accepts three new parameters that give the LLM what it needs to bootstrap analysis on raw binaries:
processor: the IDA processor module with an optional variant (e.g., arm:ARMv7-M for Cortex-M firmware, metapc:80386p for 32-bit x86, mips:mipsl for little-endian MIPS)loader: explicit loader selection (e.g., "Binary file" for raw blobs)base_address: the load address in hex or decimal (e.g., "0x08000000" for a typical STM32 flash base)For structured formats, these parameters are optional. IDA figures them out from the file headers. For raw binaries, the LLM needs to provide them. If the user says “analyze this Cortex-M firmware dump loaded at 0x08000000,” those three parameters map directly:
{
"file_path": "/path/to/firmware.bin",
"processor": "arm:ARMv7-M",
"loader": "Binary file",
"base_address": "0x08000000"
}
The server validates processor names and catches a subtle headless-mode pitfall: processor names like arm, metapc, and mips are ambiguous. In IDA’s GUI, selecting one of these pops up a dialog asking which variant you mean: ARM or AArch64? 32-bit or 64-bit x86? But headless idalib never shows that dialog. It silently picks a default, and the default is often wrong. A Cortex-M firmware blob opened with bare arm ends up disassembled as AArch64, producing nonsense.
The server rejects these bare names on raw binaries and returns the available variants with descriptions:
"arm" is ambiguous for raw binaries. It defaults to AArch64 in headless mode.
Use a specific variant:
arm:ARMv7-M Cortex-M (32-bit Thumb-2)
arm:ARMv7-A 32-bit A-profile
arm:AArch64 64-bit (explicit)
The LLM can also call list_targets to enumerate all available processors and loaders, so it can match an unknown binary to the right target without guessing.
macOS universal binaries pack multiple architecture slices into a single file. In 2.1, opening one would silently pick whichever slice IDA defaulted to, usually arm64, even when the target was x86_64. Nothing indicated the wrong slice had been selected until the disassembly didn’t make sense.
In 2.2, the server parses the fat header, identifies the available slices, and requires the caller to choose explicitly:
AmbiguousFatBinary: universal binary contains multiple architectures.
Available slices: arm64, arm64e, x86_64
Pass fat_arch="arm64" to select a slice.
Each slice gets its own .i64 sidecar (binary.arm64.i64, binary.x86_64.i64), so multiple architectures can be opened simultaneously in separate workers. Combined with execute’s cross-database support, the LLM can decompile the same function in both the arm64 and x86_64 slices and diff the pseudocode. This helps when finding platform-specific behavior, verifying that a vulnerability affects all architectures, or understanding how the compiler optimized differently for each target.
The fat header parser also handles an edge case that has bitten other tools: Java .class files share the same magic bytes (0xCAFEBABE) as Mach-O fat binaries. The parser validates slice counts and CPU types to distinguish the two, so a directory full of Java classes won’t trigger false fat-binary detection.
Not every model writes good Python, and not every MCP client needs server-side tool discovery. The meta-tools are designed to be independently useful, so you can enable the ones that match your setup and disable the ones that don’t.
Three environment variables control which meta-tools are available:
IDA_MCP_DISABLE_EXECUTE: hides the execute meta-tool. Smaller models or those without strong code generation can produce unreliable Python in execute blocks: wrong parameter names, broken control flow, off-by-one iteration. For these models, discrete tool calls are more reliable: each call is independently validated, and errors are clear and localized. Disabling execute keeps batch for bulk operations and call for hidden tools.
IDA_MCP_DISABLE_BATCH: hides the batch meta-tool. Useful if your workflow routes all multi-step work through execute anyway, since having both visible can lead the LLM to pick the wrong one.
IDA_MCP_DISABLE_TOOL_SEARCH: disables server-side progressive disclosure entirely. All ~125 tools become directly visible in the client’s tool list, and search_tools and get_schema are removed. This is the right setting for clients like Claude Code that already implement their own tool deferral. Claude Code defers tool schemas and loads them on demand. If ida-mcp is also hiding tools behind search_tools, the LLM has to go through two layers of discovery to reach a specialized tool. Disabling the server-side layer removes the redundancy.
These are environment variables on the server process, so they apply to all sessions against that daemon. Set them in your MCP client configuration:
{
"command": "ida-mcp",
"env": {
"IDA_MCP_DISABLE_TOOL_SEARCH": "1"
}
}
As a starting point: if you’re using Claude (Opus or Sonnet) through Claude Code, disable tool search. If you’re using a smaller model or a client without native tool deferral, leave everything enabled and let server-side progressive disclosure handle it.
open_database warnings (e.g., loader compatibility issues) are surfaced to the client instead of silently swallowed. When something goes wrong, you can find the relevant log without scrolling through a monolithic file.save_database and execute blocks send progress notifications every 5 seconds to prevent client timeouts on large databases. Saving a database with millions of functions and extensive annotations can take minutes; without heartbeats, the MCP client would assume the server had hung and disconnect..i64 no longer passes stale loader options that caused idalib to exit(1) on format mismatch. This was annoying because the failure mode was a silent exit with no error message: the worker just disappeared.uv tool install --upgrade ida-mcp
Or with pip:
pip install --upgrade ida-mcp
The MCP interface is backward compatible. Existing client configurations work without changes. The daemon spawns automatically on first connection.
If you run into issues or have feature requests, please open an issue on GitHub.
IDA Pro and Hex-Rays are trademarks of Hex-Rays SA. ida-mcp is an independent project and is not affiliated with or endorsed by Hex-Rays.
]]>In 2.0, all ~195 tools were registered with the MCP client at startup. Every tool’s full schema (name, description, parameters, output type) was injected into the LLM’s context window before it had even opened a binary. That’s tokens spent describing tools the LLM may never use.
In 2.1, only ~20 core tools are registered directly: the database lifecycle tools, decompile_function, list_functions, get_strings, get_xrefs_to, list_names, and a handful of others that cover the most common analysis workflows. Everything else is discoverable through two meta-tools:
search_tools — takes a keyword regex (e.g., patch|assemble, snapshot, operand) and returns matching tool names with descriptionscall_tool — invokes any tool by name, even if it wasn’t in the initial registrationWhen the LLM needs something specialized — manipulating register variables, generating FLIRT signatures — it searches for the right tool and calls it through call_tool. The full schema for that tool is fetched on demand rather than sitting in context from the start.
Opening a binary in IDA triggers auto-analysis: the passes that identify functions, resolve cross-references, recognize library code, and build the initial database. For large binaries, this can take minutes. In 2.0, open_database blocked the calling agent until analysis completed, but a second subagent could attach to an already-open database and start querying before auto-analysis had finished.
In 2.1, open_database returns immediately. Analysis runs as a background task while the LLM moves on. The caller uses wait_for_analysis to block until analysis has fully completed for a specific database. When multiple databases are being opened in parallel, wait_for_analysis accepts a list and returns as soon as any of them finish, so the LLM can start on whichever is ready first.
This lets the LLM issue multiple open_database calls before blocking on any of them. While analysis is running, tool calls to that database return an error rather than silently operating on incomplete data. The state machine is explicit: open, wait, query.
Several tools now accept batched inputs to reduce round-trip overhead:
decompile_function — up to 50 addresses in a single callget_xrefs_to — up to 50 addresses with direction controlget_strings — up to 10 filter patternsEach tool call is a full MCP round trip, so batching 20 decompile calls into one eliminates 19 round trips.
find_code_by_stringThis new composite tool combines what used to be a multi-step workflow: search for a string literal, find cross-references to that string’s address, and resolve those references to their containing functions — all in one call. Previously the LLM had to chain get_strings → get_xrefs_to → get_function manually, requiring three tool calls and holding intermediate results in context. find_code_by_string does the full pipeline server-side.
When multiple subagents share the same ida-mcp server, 2.0 had no concept of which agent “owned” which database. Any agent could close any database, potentially pulling the rug out from under a sibling.
In 2.1, workers track which MCP sessions (agents) are attached. close_database detaches the calling session and only terminates the worker when no sessions remain. list_databases now reports session counts and whether the calling agent is attached to each database. Subagents can now work concurrently on shared databases without interfering with each other.
MainThreadExecutor that enforces idalib’s thread affinity requirements. The MCP event loop runs on a background thread, avoiding the deadlock scenarios that could occur in 2.0 when analysis callbacks and tool calls competed for the main thread.output_schema, so MCP clients with structured output support can parse responses programmatically instead of parsing text.readOnlyHint, destructiveHint, and idempotentHint, letting clients distinguish safe reads from mutations and prompt for confirmation on destructive operations.parse_address() now resolves symbol names before falling back to bare hex interpretation. In 2.0, a function named add or dead would be interpreted as the hex value 0xadd or 0xdead instead of as a symbol lookup. This was subtle and maddening.I ran the same analysis task against both versions on a large, stripped macOS application bundle (multiple binaries, 200MB+ of ARM64 code). Same prompt, same binaries, same hardware, Claude Opus orchestrating parallel subagents.
The most visible difference was function discovery. The 2.0 run found roughly 4,000 functions in the main binary and 3,600 in the main framework, limited to the Objective-C methods with surviving selector names. The 2.1 run found 1.26 million and 570,000 respectively. Same binaries.
In the 2.0 run, subagents started querying before auto-analysis had finished discovering functions in the stripped code. In 2.1, wait_for_analysis ensured analysis was complete before any queries ran. Those additional sub_* routines are where the actual implementation lives; without them, the LLM only sees the Objective-C dispatch layer and misses the C/C++ engine underneath.
The end results reflected the difference in visibility. The 2.0 run produced output derived mostly from string literals and Objective-C class names: what the code talks about but not what it does. The 2.1 run produced output derived from actual decompiled logic: specific function addresses, byte-level protocol details, and enum values extracted from the code itself.
On the efficiency side, the two runs made a comparable number of tool calls (2.0: 234, 2.1: 257), but 2.1’s batching and find_code_by_string meant each call covered more ground. The bigger gain was context window usage: 195 tool schemas registered upfront in 2.0 vs 20 in 2.1, with the rest discovered on demand. That frees up context for actual analysis.
uv tool install --upgrade ida-mcp
Or with pip:
pip install --upgrade ida-mcp
The MCP interface is backward compatible. Existing client configurations work without changes.
If you run into issues or have feature requests, please open an issue on GitHub.
IDA Pro and Hex-Rays are trademarks of Hex-Rays SA. ida-mcp is an independent project and is not affiliated with or endorsed by Hex-Rays.
]]>ida-mcp is built on idalib and exposes ~190 tools covering:
Every tool accepts addresses in hex (0x401000), decimal, or as a symbol name, and list operations use offset/limit pagination.
All mutation tools return old_* fields showing the previous state — old_comment, old_name, old_color, old_bytes, etc. — so the LLM can see what changed without a separate read-back call.
For anything the built-in tools don’t cover, run_script allows arbitrary IDAPython execution (enabled by the IDA_MCP_ALLOW_SCRIPTS environment variable).
MCP defines three primitives: tools (actions), resources (read-only context), and prompts (guided workflows). Most IDA MCP servers only implement tools; ida-mcp 2.0 implements all three.
Resources are read-only endpoints that provide context without consuming a tool call. ida-mcp exposes 36 of them via ida:// URIs, organized into four tiers:
Core context — database metadata, file paths, processor info, segments, entry points, imports, exports, and a statistics summary. These give the LLM orientation when it first opens a binary.
Structural reference — the local type catalog, individual type definitions, structure layouts with member offsets, enum definitions, and applied FLIRT/TIL signatures. These let the LLM inspect the type system without calling tools.
Browsable collections — functions, strings, named locations, and bookmarks. Enough for the LLM to get a high-level picture of the binary.
Most collection resources also expose a search/{pattern} variant for filtering by name or address, so the LLM can narrow results without paging through large lists.
Per-entity lookups — function metadata, stack frames, exception handlers, decompiled variables, and cross-references by address. These are parameterized URIs like ida://functions/{addr} and ida://xrefs/to/{addr}.
In multi-database mode, the supervisor proxies resource reads to the appropriate worker and exposes its own ida://databases resource listing all open databases with worker status.
ida-mcp includes 8 prompts — structured analysis templates that guide the LLM through multi-step workflows:
Analysis:
survey_binary — binary triage: identify the file type, architecture, key functions, strings of interest, and imports. Accepts an optional focus parameter to narrow the survey.analyze_function — single-function deep dive with data flow analysis and security notes.diff_before_after — preview how a rename or retype will affect the decompiler output before committing.classify_functions — group functions by behavioral pattern (crypto, networking, string manipulation, etc.) to prioritize analysis effort.Security:
find_crypto_constants — scan for known constants from AES, SHA-256, SHA-1, MD5, CRC-32, ChaCha20, RSA, and Blowfish.Workflow:
auto_rename_strings — suggest function renames based on unique string references, without applying any changes.apply_abi — apply type information for a known ABI (Linux syscalls, libc, Windows API, POSIX).export_idc_script — generate a reproducible IDAPython script capturing all annotations made during the session.Reverse engineering rarely involves a single binary. You might need to cross-reference a DLL against its loader, compare two firmware versions, or analyze a malware dropper alongside its payload. With ida-mcp 1.x, you had to close one database before opening another. With ida-mcp 2.0, you can keep them all open at once.
ida-mcp runs a supervisor process that spawns worker subprocesses on demand. Each worker loads idalib independently and manages a single database. The supervisor proxies MCP tool calls to the appropriate worker based on a database parameter it injects into every tool’s schema.
MCP Client ←—stdio—→ Supervisor (ProxyMCP)
│
├——stdio——→ Worker 1 (binary_a.exe)
├——stdio——→ Worker 2 (library.dll)
└——stdio——→ Worker 3 (firmware.bin)
This is a direct consequence of idalib’s threading model: all IDA API calls must happen on the thread that imported the idapro module, and global state is shared per-process. Rather than fighting that, each database gets its own process with complete isolation.
This means the LLM never pays a context-switch penalty. In a serial setup, switching from one binary to another means closing the current database and reopening the next one — a swap that flushes all in-memory state and can take seconds depending on database size. With per-database workers, the LLM just passes a different database parameter and gets an immediate response. All databases stay warm.
This matters most when the LLM is using subagents. An orchestrating agent can spawn parallel subagents — one reversing a loader, another analyzing the payload it drops, a third inspecting a shared library — and they all run concurrently against their own workers without blocking each other. No subagent has to wait for another to release the database.
To use it, pass keep_open=True when opening a database:
# First binary — opens normally
open_database("/path/to/binary_a.exe", keep_open=True)
# Second binary — previous database stays open
open_database("/path/to/library.dll", keep_open=True)
# Tools target a specific database
decompile_function("main", database="binary_a.exe")
get_xrefs_to("ImportantExport", database="library.dll")
Idle workers are cleaned up after a configurable timeout (default 30 minutes, controlled by IDA_MCP_IDLE_TIMEOUT), and the maximum number of concurrent workers can be capped with IDA_MCP_MAX_WORKERS.
If you don’t need multi-database support, the ida-mcp-worker entry point provides the same single-database behavior as 1.x.
ida-mcp is not the only IDA MCP server. The existing servers fall into two categories: plugin-based servers that run inside a GUI session, and headless servers that run standalone without a GUI.
The plugin-based approach is the most common. The most popular is ida-pro-mcp by mrexodia (of x64dbg fame), which runs as an IDA plugin communicating over SSE or stdio and exposes a large tool set. Others in this category include ida-multi-mcp (multi-instance routing through a single MCP endpoint), IDA-MCP (a gateway architecture supporting multiple IDA instances), and IDAssistMCP. Plugin-based servers require a running GUI session, which ties the server’s lifecycle to a visible IDA window.
On the headless side:
ida-pro-mcp includes idalib-mcp, a headless mode built on the same idalib foundation as ida-mcp. It exposes ~76 tools (96 with the debugger extension) plus 11 MCP resources, serving over HTTP/SSE. Requirements are IDA 8.3+ and Python 3.11+. The multi-database mode works by swapping the active database in a single process — only one is loaded at a time.
ida-mcp-rs links directly against IDA’s native libraries from Rust. It has first-class support for Apple’s dyld_shared_cache, useful if you work with macOS/iOS binaries. The tool surface is smaller (~11 tools) and focused on core analysis operations.
headless-ida-mcp-server uses IDA’s headless executable (idat) rather than idalib, which avoids the idalib dependency but routes through a separate process for each API call.
ida-mcp shares the idalib foundation with idalib-mcp but takes a different approach: stdio transport instead of HTTP/SSE, per-database subprocess isolation instead of serial database swapping, and automatic idalib discovery instead of requiring a pip install. ida-mcp requires IDA Pro 9+ and Python 3.12+; idalib-mcp supports IDA 8.3+ and Python 3.11+ and includes debugger tools that ida-mcp does not have yet.
ida-mcp requires IDA Pro 9+ with a valid license and Python 3.12+. A Hex-Rays decompiler license is needed for decompilation tools but is not required for the rest.
# Install from PyPI
uv tool install ida-mcp
IDA Pro is found automatically from standard installation paths, or you can set IDADIR to point to your installation.
Then configure your MCP client to launch the server. If you prefer not to install globally, uvx can fetch and run it on demand:
{
"mcpServers": {
"ida": {
"command": "uvx",
"args": ["ida-mcp"]
}
}
}
No plugin files to copy, no ports to configure, no GUI to keep running.
If you run into issues or have feature requests, please open an issue on GitHub.
IDA Pro and Hex-Rays are trademarks of Hex-Rays SA. ida-mcp is an independent project and is not affiliated with or endorsed by Hex-Rays.
]]>Many third-party component vendors distribute SPICE models exclusively as PSpice-encrypted files, locking them to a single simulator and preventing their use in open-source and alternative tools such as NGSpice, Xyce, and PySpice. As part of research into these encryption schemes, I’ve released SpiceCrypt — a Python library and CLI tool that decrypts encrypted SPICE model files, restoring interoperability so engineers can use lawfully obtained models in any simulator.
PSpice supports six encryption modes (0–5). Modes 0–3 and 5 derive all key material from constants hardcoded in the binary; once those constants are extracted, files in these modes can be decrypted directly. Mode 4 is the only mode that incorporates user-supplied key material: vendors provide a key string via a CSV file referenced by the CDN_PSPICE_ENCKEYS environment variable. This key is XOR’d with the hardcoded base keys during derivation, so decryption requires the same key file. A bug in key derivation reduces the effective keyspace to 2^32, making the user key recoverable by brute force in seconds.
Mode 4 uses AES-256 in ECB mode. Key derivation starts from two base strings:
g_desKey: a 4-byte “short” base key ("8gM2")g_aesKey: a 27-byte “extended” base key ("H41Mlwqaspj1nxasyhq8530nh1r")When a user provides a key via the CDN_PSPICE_ENCKEYS CSV file, user key bytes 0–3 are XOR’d into the short base, and bytes 4–30 are XOR’d into the extended base. A version suffix (e.g., "1002") is then appended to each base key.
PSpiceAESEncoder_setKey receives only the short key (g_desKey), not the extended key (g_aesKey). The 32-byte AES-256 key is constructed by zero-padding this null-terminated string:
Byte 0–3: XOR("8gM2", user_key[0:4]) -- unknown (4 bytes)
Byte 4–7: "1002" -- version suffix (atoi(version_string) + 999)
Byte 8: 0x00 (null terminator) -- known
Byte 9–31: 0x00 (zero padding) -- known
EncryptionContext_init calls initEncryptionKeys to derive both keys, then passes only g_desKey to the cipher engine via a vtable call:
lea rdx, g_desKey ; short key loaded as setKey argument
...
call qword ptr [rax] ; vtable[0]: setKey(&g_desKey)
PSpiceAESEncoder_setKey copies this null-terminated string into a zero-filled 32-byte local buffer and calls AES_keyExpansion(self+8, keyBuf, 256). g_desKey in mode 4 is 8 characters (4 XOR’d bytes + "1002") followed by a null terminator, so bytes 9–31 of the AES key are always zero.
Since 28 of 32 key bytes are known, the effective keyspace shrinks from 2^256 to 2^32.
In practice the keyspace is even smaller: since user keys are stored in a CSV file, each byte is almost certainly printable ASCII (0x20–0x7E), reducing the search space to roughly 95^4 (~81 million candidates). SpiceCrypt does not exploit this observation — exhausting the full 2^32 space is fast enough that filtering by character class would add complexity without meaningful benefit.
The first encrypted block after every $CDNENCSTART marker is a metadata header whose plaintext always begins with the fixed prefix "0001.0000 " (10 ASCII bytes). This prefix falls entirely within the first 16-byte AES sub-block, providing a known-plaintext crib for validating candidate keys.
The attack:
"0001.0000 ", the candidate is correct.Exhaustive search of all 2^32 candidates takes seconds with AES-NI, or under 1 second on a GPU.
SpiceCrypt implements this attack with a hardware-accelerated Rust extension (AES-NI / ARM Crypto Extensions) for key recovery:
# Brute-force recover the user key (~seconds on modern hardware)
spice-crypt --recover-key encrypted_file.lib
# Decrypt with a known user key
spice-crypt --user-key KEY encrypted_file.lib
Once the 4-byte brute-force attack succeeds, the full user key is recoverable. The metadata header’s plaintext contains the derived g_aesKey: the extended base XOR’d with user key bytes, with the version suffix appended.
Short user key (bytes 0–3): XOR the recovered 4 bytes with the known base "8gM2".
Extended user key (bytes 4–30): Decrypt the metadata header with the recovered AES key. The embedded g_aesKey equals XOR("H41Mlwqaspj1nxasyhq8530nh1r", user_key[4:31]) + "1002". Strip the version suffix and XOR with the known base to recover the remaining 27 user key bytes.
The entire user key string from the CSV file is now known, and all files encrypted with that key are compromised.
The names g_desKey and g_aesKey are reverse-engineered labels, not original source names. The key sizes suggest the extended key was intended for AES and the short key for DES. The short key is 8 bytes after derivation, matching a DES key size. The extended key is 31 bytes plus a null terminator to fill 32 bytes, which is likely an off-by-one error since AES-256 requires 32 bytes of key material. Passing the short key to the AES engine appears to be a copy-paste error from the DES code path. Had the extended key been used, the effective keyspace would be 2^216, making a brute-force attack infeasible.
AES-256 encryption support was introduced in PSpice 16.6 (April 2014), alongside the existing DES-based modes. The bug has presumably been present since that release. Fixing it now would break compatibility with every encrypted model created in the twelve years since its introduction.
SpiceCrypt is a tool I’ve released that handles decryption of all PSpice encryption modes, as well as LTspice encryption formats. It can be installed from PyPI:
pip install spice-crypt
All encryption formats are auto-detected:
# Decrypt any encrypted SPICE model file
spice-crypt encrypted_file.lib
# Decrypt to an output file
spice-crypt -o decrypted.lib encrypted_file.lib
SpiceCrypt also provides a Python API for programmatic use:
from spice_crypt import decrypt_stream
plaintext, verification = decrypt_stream("encrypted.lib")
Beyond PSpice, SpiceCrypt supports LTspice’s text-based DES format and Binary File format. Full details on all supported formats, the Python API, and the legal basis for this interoperability work are available in the project README.
Disclaimer: SpiceCrypt is intended solely for enabling simulator interoperability with lawfully obtained models. Using it to violate intellectual property rights is immoral and is not an acceptable use of the tool.
PSpice is a trademark of Cadence Design Systems, Inc.
]]>To help keep me honest and support a worthy cause, I pledged to donate $100 to the Ukraine Humanitarian Fund for each day I failed to write a post.
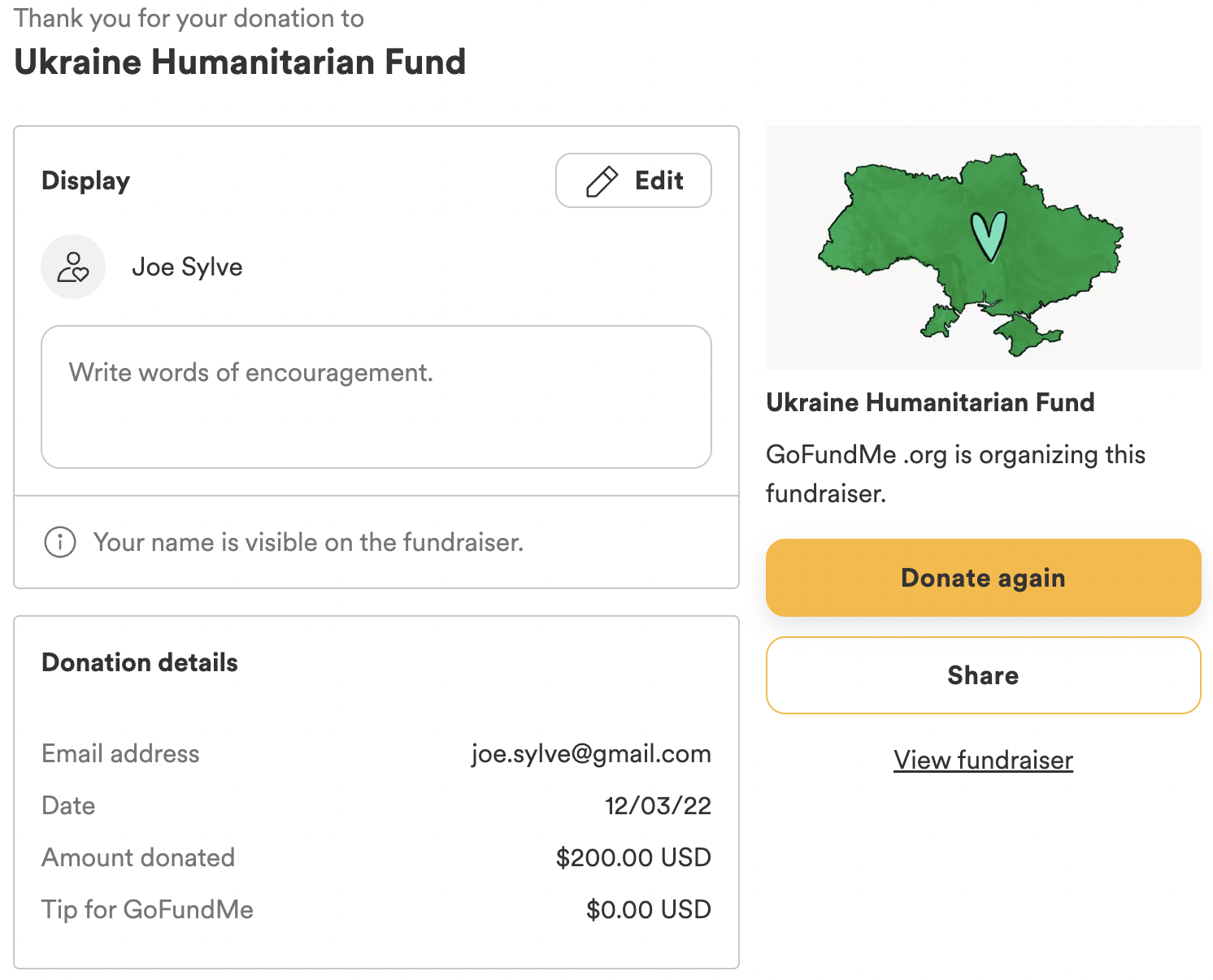
Early on, I decided to change the challenge’s parameters from posting every day until Christmas to posting every weekday in December. Because that changed the maximum number of posts from 24 to 22, I donated $200 on December 3rd.
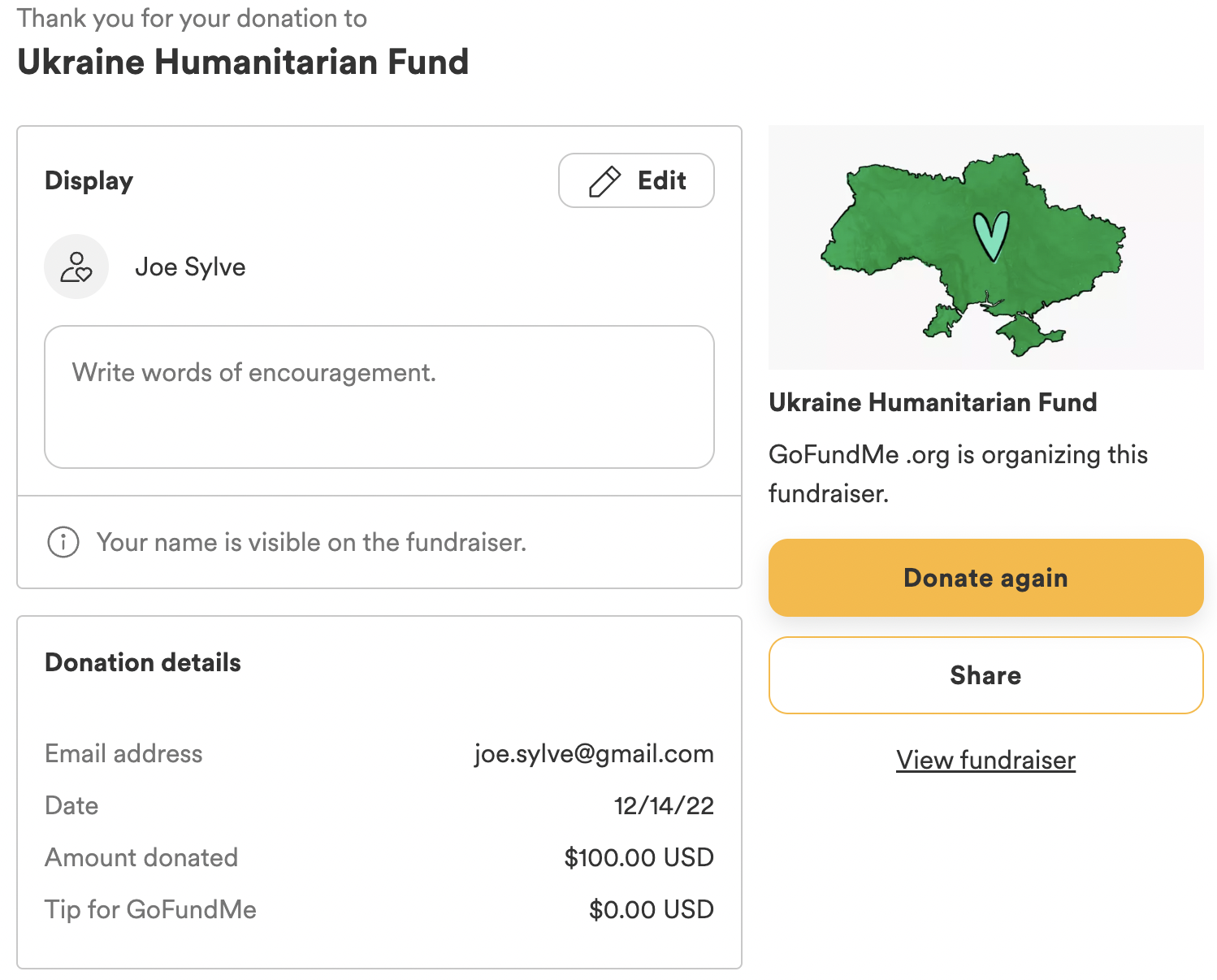
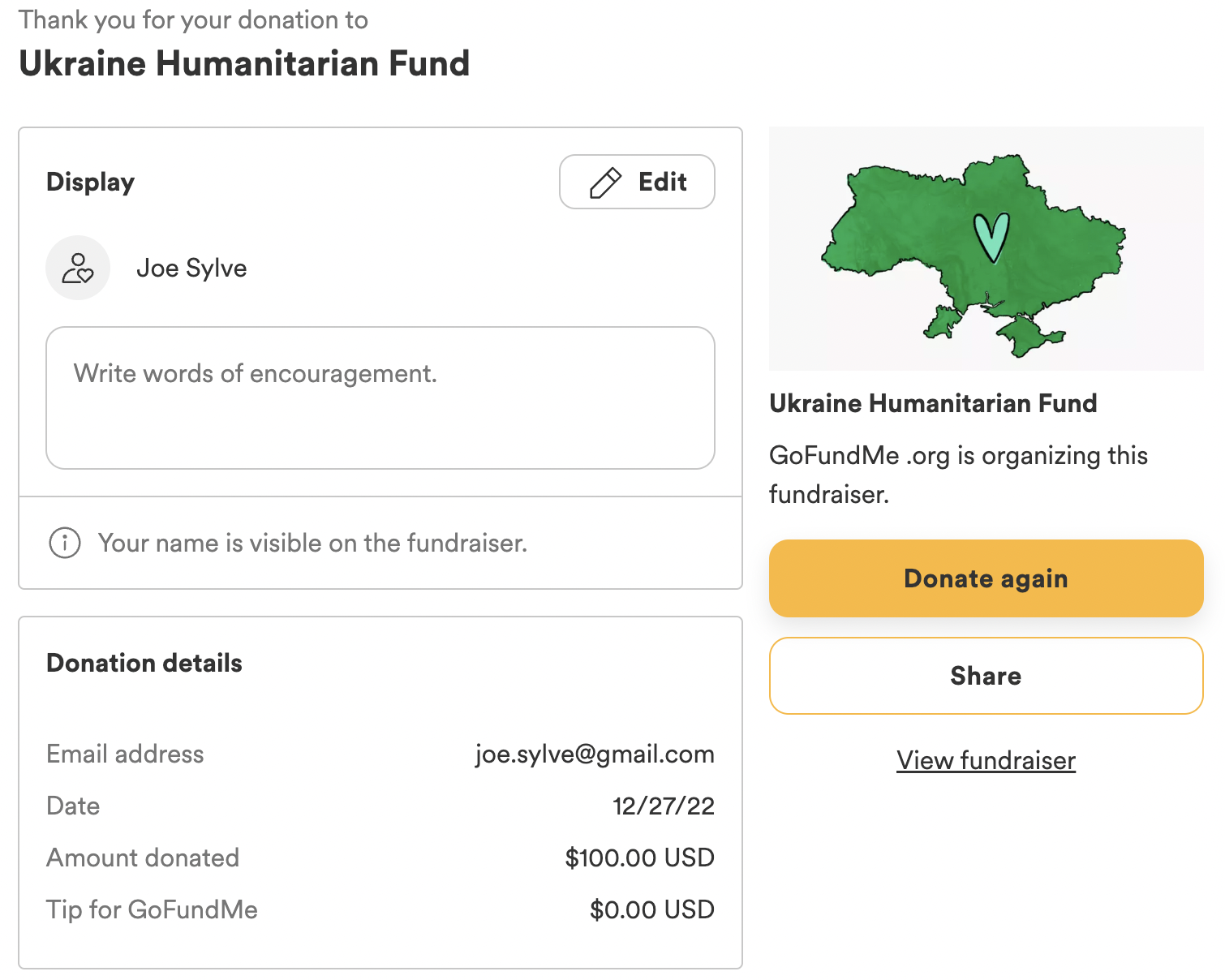
I donated an additional $100 per day on days 10 and 19 when my recently diagnosed carpal tunnel syndrome symptoms were especially bothersome.
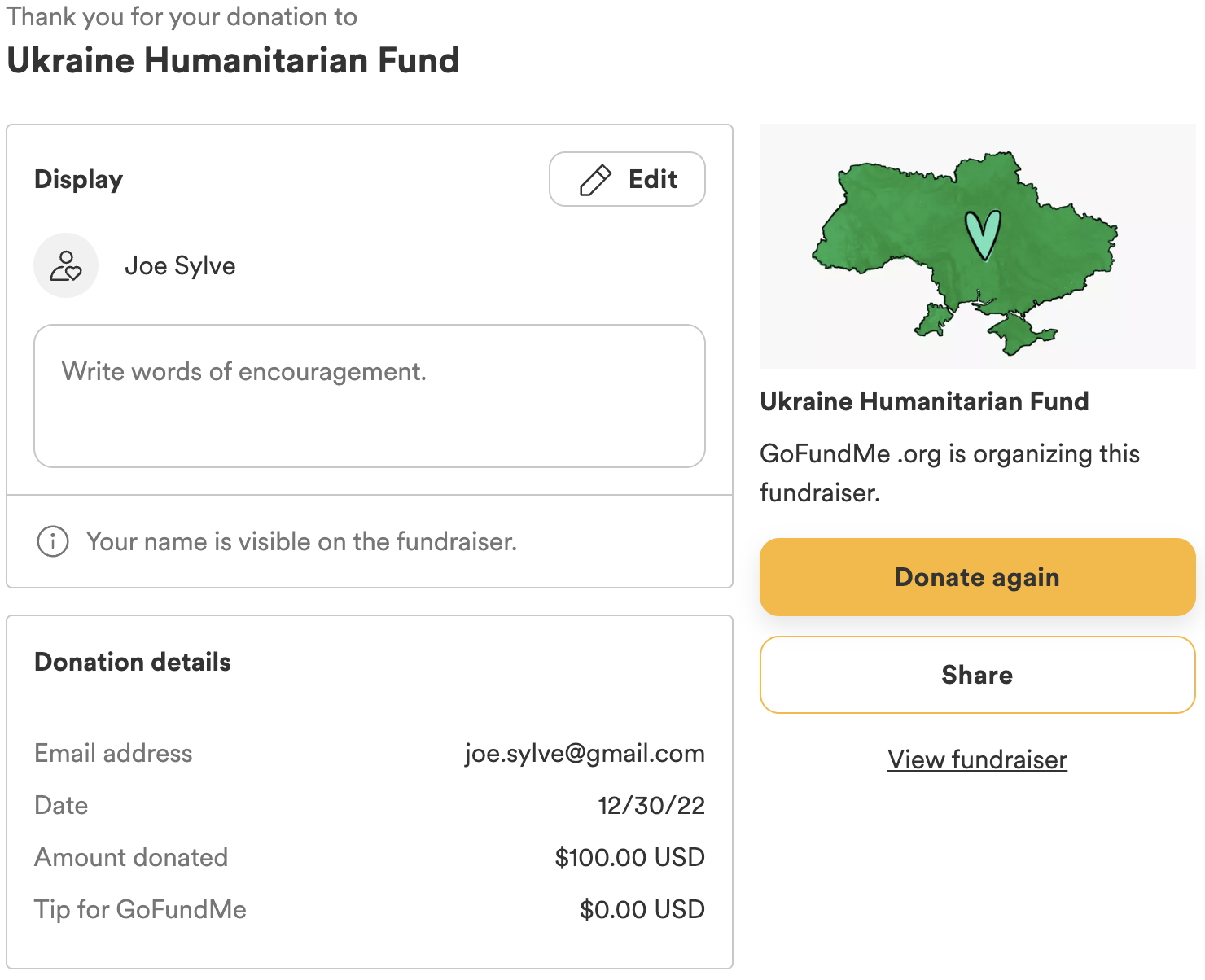
Because I like round numbers, support the cause, and I’m not sure if today’s post counts, I have donated an additional $100, bringing my total contribution to the fund to $500 for this challenge.
If it is within your means, please donate to help the Ukrainian people. Regardless of your politics, the civilians that have lost everything due to this senseless conflict are blameless and deserving of our support.
I decided to start this blog as part of my resolution to write more in 2023 and share my research. The advent challenge was a good way of kick-starting that effort. I plan on continuing to post, albeit at a much less demanding pace. If there are any topics about APFS or anything else in digital forensics that you are interested in learning more about, please feel free to reach out to me. I’ve decided to sunset my Twitter account, but you’ll find me active on Mastodon @jtsylve@infosec.exchange.
]]>Both the SSD and HDD of a Fusion Drive appear to macOS as separate physical disk devices. Both disks are GPT partitioned with a standard EFI partition and a second, larger partition, which takes up the bulk of the space on disk. For example, running the command diskutil list may show the HDD as /dev/disk0 with its primary partition as /dev/disk0s2 and the SSD as /dev/disk1 and /dev/disk1s2. These two partitions make up the physical stores of the Fusion Container.
Each physical store is formatted separately in much the same way as any other APFS container. Both will share the same nx_uuid in their NX Superblocks and have a separate, nearly-identical UUID in the nx_fusion_uuid field, with the most significant bit being cleared on the tier1 SSD partition and set on the tier2 HDD partition. The combination of these UUIDs can be used to identify the physical storage tiers of the container.
Both tiers are mapped together as a single “synthesized” container and are presented to macOS as a single logical block device (for example, /dev/disk2). The tier1 blocks are mapped at logical byte offset zero, and the tier2 blocks at 4 EiB. The offsets within the exabyte-scale gap between the two sets of blocks cannot be read.
APFS objects and blocks can be stored on either (or both) tiers, and their physical addresses will require some simple translation as follows:
#define FUSION_TIER2_DEVICE_BYTE_ADDR 0x4000000000000000ULL
const paddr_t first_tier2_block = FUSION_TIER2_DEVICE_BYTE_ADDR / nxsb->block_size;
if (paddr < first_tier2_block) {
tier1->read_block(paddr);
} else {
tier2->read_block(paddr – first_tier2_block);
}
The logically exabyte-scale gap separating the two tiers presents a unique problem during digital forensic imaging of Fusion Containers. To preserve the logical offsets of the evidence without having to use a data center worth of storage, you must use an evidence storage format that supports sparse imaging. As long as this is considered along with the additional physical address translation described above, analyzing Fusion Containers does not generally differ from analyzing other APFS containers.
]]>The Snapshot Metadata Tree is a B-Tree whose physical address can be located by reading the apfs_snap_meta_tree_oid field of the Volume Superblock. It stores two types of objects, structured as File System Records.
Snapshot Metadata Records store the bulk of metadata about Volume Snapshots. The key-half is a j_snap_metadata_key structure with an encoded type of APFS_TYPE_SNAP_METADATA.
typedef struct j_snap_metadata_key {
j_key_t hdr; // 0x00
} j_snap_metadata_key_t; // 0x08
hdr: The record’s header. The object identifier in the header is the snapshot’s transaction identifier.The value-half of the record is a j_snap_metadata_val_t structure and is immediately followed by the UTF-8 encoded name of the snapshot.
typedef struct j_snap_metadata_val {
oid_t extentref_tree_oid; // 0x00
oid_t sblock_oid; // 0x08
uint64_t create_time; // 0x10
uint64_t change_time; // 0x18
uint64_t inum; // 0x20
uint32_t extentref_tree_type; // 0x28
uint32_t flags; // 0x2C
uint16_t name_len; // 0x30
uint8_t name[0]; // 0x32
} j_snap_metadata_val_t;
extentref_tree_oid: The physical object identifier of the B-Tree that stores extent references for the snapshot.sblock_oid: The physical object identifier of a backup of the snapshot’s Volume Superblockcreate_time: The time when the snapshot was createdchange_time: The time that this snapshot was last modifiedinum: reservedextentref_tree_type: The type of the Extent Reference Treeflags: A bit field that contains additional information about a snapshot metadata recordname_len: The length of the name that follows this structure (in bytes)| Name | Value | Description |
|---|---|---|
| SNAP_META_PENDING_DATALESS | 0x00000001 | This snapshot is dataless, meaning that it does not preserve the file extents |
| SNAP_META_MERGE_IN_PROGRESS | 0x00000002 | The snapshot is in the process of being merged with another |
Snapshot Name Records are used to map snapshot names to their transaction identifiers. The key-half of the record is a j_snap_name_key_t structure with an encoded type of APFS_TYPE_SNAP_NAME. It is followed by the UTF-8 encoded name of the snapshot.
typedef struct j_snap_name_key {
j_key_t hdr; // 0x00
uint16_t name_len; // 0x08
uint8_t name[0]; // 0x0A
} j_snap_name_key_t;
hdr: The record’s header. The object identifier can be ignored.name_len: The length of the name (in bytes)name: The start of the UTF-8 encoded nameThe value-half is a j_snap_name_val_t structure.
typedef struct j_snap_name_val {
xid_t snap_xid; // 0x00
} j_snap_name_val_t; // 0x08
snap_xid: The transaction identifier of the snapshotEach snapshot has a virtual Snapshot Extended Metadata Object in the volume’s Object Map. The virtual object identifier of this object is stored in the apfs_snap_meta_ext_oid field of the Volume Superblock. There are multiple versions of this object whose transaction identifiers correspond to each snapshot.
typedef struct snap_meta_ext_obj_phys {
obj_phys_t smeop_o; // 0x00
snap_meta_ext_t smeop_sme; // 0x20
} snap_meta_ext_obj_phys_t; // 0x48
smeop_o: The object’s headersmeop_sme: The snapshot’s extended metadatatypedef struct snap_meta_ext {
uint32_t sme_version; // 0x00
uint32_t sme_flags; // 0x04
xid_t sme_snap_xid; // 0x08
uuid_t sme_uuid; // 0x10
uint64_t sme_token; // 0x20
} snap_meta_ext_t; // 0x28
sme_version: The version of this structure (currently 1)sme_flags: A bitfield of flags (none are currently defined)sme_snap_xid: The transaction identifier of the snapshotsme_uuid: The unique identifier of the snapshotsme_token: An opaque token (reserved)All encryption in APFS is based on the XTS-AES-128 cipher, which uses a 256-bit key and a 64-bit “tweak” value. This tweak value is position dependent. It allows the same plaintext to be encrypted and stored in different locations on disk and have drastically different ciphertext while using the same AES key. Every 512 bytes of encrypted data uses a tweak based on the container offset of the block’s initial storage.
Knowledge of the AES key alone is not always enough for successful decryption. If the encrypted block is ever relocated on disk, the data is not guaranteed to be re-encrypted with a new tweak. In these cases, the tweak can not be inferred based on the block’s on-disk location, so we must learn the original tweak value used for encryption.
There are primarily two sets of data protected with the APFS Volume Encryption Key: File System Tree Nodes and File Extents. As we’ve discussed, File System Tree Nodes store the File System Records that contain the file system’s metadata, and File Extents contain the bulk of the data stored in a file’s Data Streams.
A volume’s Object Map is never encrypted, but its referenced virtual objects may be, as is the case with FS-Tree Nodes on encrypted volumes.
Let’s revisit the value half of an Object Map entry.
typedef struct omap_val {
uint32_t ov_flags; // 0x00
uint32_t ov_size; // 0x04
paddr_t ov_paddr; // 0x08
} omap_val_t; // 0x10
If the ov_flags bit-field member has the OMAP_VAL_ENCRYPTED flag set, then the virtual object located at ov_paddr is encrypted. These objects are never relocated without being re-encrypted, so the tweak of the first 512 bytes of data can be determined by the physical location of the data using the following logic, with the following tweak values incremented for each subsequent 512 bytes of data:
uint64_t tweak0 = (ov_paddr * block_size) / 512;
Extent data can be relocated on disk and is not guaranteed to be re-encrypted. Due to this, the initial tweak value is stored in the crypto_id field of the j_file_extent_val_t file system record:
typedef struct j_file_extent_val {
uint64_t len_and_flags; // 0x00
uint64_t phys_block_num; // 0x08
uint64_t crypto_id; // 0x10
} j_file_extent_val_t; // 0x18
We’ve now discussed all of the information needed to access data on software-encrypted APFS volumes. This decryption requires the knowledge of the password of any user on the system or one of the various recovery keys. While APFS hardware encryption works in largely the same manner, the encryption also depends on keys that are stored within the specific security chip on a given system. There are currently no known methods of extracting these chip-specific keys; therefore, the data on hardware-encrypted devices must be decrypted at acquisition time on the device itself. The only software that I am aware of that is capable of this is Cellebrite’s Digital Collector.
Full disclosure: I currently work for Cellebrite and helped develop these capabilities. I do not directly profit from the sales of Digital Collector but felt it appropriate to disclose my association when linking to a commercial product. I am not trying to sell you anything. Unfortunately, I am also not at liberty to discuss the methodology used to facilitate this decryption.
]]>std::experimental::simd to speed up APFS Fletcher-64 calculations. It turns out that there were still some low-hanging optimizations that could be used to improve my code. I got better performance from my code by using a simple loop unrolling technique.
Here’s the new version of the function. Notice that the only difference is that I’m now calculating more data per iteration of the loop. I’m using a lambda here to avoid code duplication, but the compiler will gladly inline the code.
static uint64_t fletcher64_simd(std::span<const uint32_t, 1024> words) {
vu64 sum1{};
sum1[0] = -(static_cast<uint64_t>(words[0]) + words[1]);
vu64 sum2{};
sum2[0] = words[1];
const auto calc = [&](size_t n) {
sum2 += vu32::size() * sum1;
const vu64 all{reinterpret_cast<const uint64_t*>(std::addressof(words[n])),
stdx::vector_aligned};
const vu64 evens = all & max32;
const vu64 odds = all >> 32;
sum1 += evens + odds;
sum2 += evens * even_m + odds * odd_m;
};
for (size_t n = 0; n < words.size(); n += vu32::size()) {
calc(n);
calc(n += vu32::size());
calc(n += vu32::size());
calc(n += vu32::size());
calc(n += vu32::size());
calc(n += vu32::size());
calc(n += vu32::size());
calc(n += vu32::size());
}
// Fold the 64-bit overflow back into the 32-bit value
const auto fold = [&](uint64_t x) {
x = (x & max32) + (x >> 32);
return (x == max32) ? 0 : x;
};
const uint64_t low = fold(stdx::reduce(sum1));
const uint64_t high = fold(stdx::reduce(sum2));
const uint64_t ck_low = max32 - ((low + high) % max32);
const uint64_t ck_high = max32 - ((low + ck_low) % max32);
return ck_low | ck_high << 32;
}
Here are the updated relative performance statistics with the updated code running on the same hardware as yesterday’s tests. Amazing!
| Target Architecture | Time per Checksum | Throughput | Speedup |
|---|---|---|---|
| SSE | 217ns | 17.5543 GiB/s | 3.4x |
| AVX2 | 105ns | 36.2421 GiB/s | 7x |
| AVX-512 | 75ns | 50.7305 GiB/s | 9.7x |
| NEON | 171ns | 22.273 GiB/s | 2.7x |
{kind=link}
{kind=link}
{kind=link}
{kind=link}